
[ad_1]

Ars Technica
On Monday, researchers from Microsoft launched Kosmos-1, a multimodal mannequin that may reportedly analyze pictures for content material, resolve visible puzzles, carry out visible textual content recognition, go visible IQ assessments, and perceive pure language directions. The researchers imagine multimodal AI—which integrates totally different modes of enter resembling textual content, audio, pictures, and video—is a key step to constructing synthetic common intelligence (AGI) that may carry out common duties on the stage of a human.
“Being a primary a part of intelligence, multimodal notion is a necessity to attain synthetic common intelligence, by way of information acquisition and grounding to the actual world,” the researchers write of their educational paper, “Language Is Not All You Want: Aligning Notion with Language Fashions.”
Visible examples from the Kosmos-1 paper present the mannequin analyzing pictures and answering questions on them, studying textual content from a picture, writing captions for pictures, and taking a visible IQ take a look at with 22–26 % accuracy (extra on that under).
-
A Microsoft-provided instance of Kosmos-1 answering questions on pictures and web sites.
Microsoft -
A Microsoft-provided instance of “multimodal chain-of-thought prompting” for Kosmos-1.
Microsoft -
An instance of Kosmos-1 doing visible query answering, supplied by Microsoft.
Microsoft
Whereas media buzz with information about massive language fashions (LLM), some AI consultants level to multimodal AI as a possible path towards common synthetic intelligence, a hypothetical expertise that may ostensibly have the ability to substitute people at any mental process (and any mental job). AGI is the said aim of OpenAI, a key enterprise companion of Microsoft within the AI house.
On this case, Kosmos-1 seems to be a pure Microsoft challenge with out OpenAI’s involvement. The researchers name their creation a “multimodal massive language mannequin” (MLLM) as a result of its roots lie in pure language processing like a text-only LLM, resembling ChatGPT. And it exhibits: For Kosmos-1 to simply accept picture enter, the researchers should first translate the picture right into a particular sequence of tokens (principally textual content) that the LLM can perceive. The Kosmos-1 paper describes this in additional element:
For enter format, we flatten enter as a sequence adorned with particular tokens. Particularly, we use <g> and </g> to indicate start- and end-of-sequence. The particular tokens <picture> and </picture> point out the start and finish of encoded picture embeddings. For instance, “<g> doc </g>” is a textual content enter, and “<s> paragraph <picture> Picture Embedding </picture> paragraph </s>” is an interleaved image-text enter.
… An embedding module is used to encode each textual content tokens and different enter modalities into vectors. Then the embeddings are fed into the decoder. For enter tokens, we use a lookup desk to map them into embeddings. For the modalities of steady alerts (e.g., picture, and audio), additionally it is possible to symbolize inputs as discrete code after which regard them as “overseas languages”.
Microsoft skilled Kosmos-1 utilizing information from the online, together with excerpts from The Pile (an 800GB English textual content useful resource) and Frequent Crawl. After coaching, they evaluated Kosmos-1’s skills on a number of assessments, together with language understanding, language technology, optical character recognition-free textual content classification, picture captioning, visible query answering, net web page query answering, and zero-shot picture classification. In lots of of those assessments, Kosmos-1 outperformed present state-of-the-art fashions, in line with Microsoft.
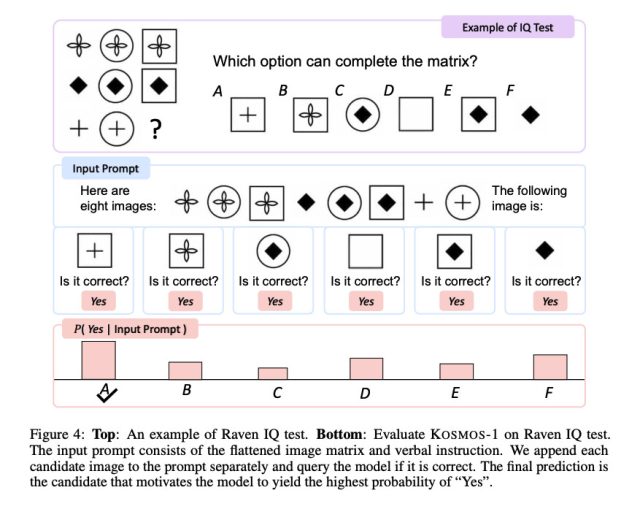
Microsoft
Of explicit curiosity is Kosmos-1’s efficiency on Raven’s Progressive Reasoning, which measures visible IQ by presenting a sequence of shapes and asking the take a look at taker to finish the sequence. To check Kosmos-1, the researchers fed a filled-out take a look at, one after the other, with every possibility accomplished and requested if the reply was appropriate. Kosmos-1 might solely appropriately reply a query on the Raven take a look at 22 % of the time (26 % with fine-tuning). That is on no account a slam dunk, and errors within the methodology might have affected the outcomes, however Kosmos-1 beat random probability (17 %) on the Raven IQ take a look at.
Nonetheless, whereas Kosmos-1 represents early steps within the multimodal area (an method additionally being pursued by others), it is easy to think about that future optimizations might deliver much more important outcomes, permitting AI fashions to understand any type of media and act on it, which can vastly improve the skills of synthetic assistants. Sooner or later, the researchers say they’d wish to scale up Kosmos-1 in mannequin measurement and combine speech functionality as effectively.
Microsoft says it plans to make Kosmos-1 obtainable to builders, although the GitHub web page the paper cites has no apparent Kosmos-specific code upon this story’s publication.
[ad_2]
Source link

